At the AI Builders Brisbane July 2025 Meetup, I gave a 2025 edition of my 'How Not to Translate a Videogame' talk from 2019. The talk explored how recent advances in AI, especially agentic capabilities, improved the scope and quality of the outcomes possible from "hobby-level" effort into automated translation of a relatively obscure Japanese visual novel, '12Riven' - the final game in a series of four that all otherwise have official or fan translations available.
The 2019 approach
The approach in 2019 relied on a pipeline of realtime text detection, recognition, and machine translation to produce a translated version of text from the game as it appeared. That translated text would then be displayed in a separate window. Even with the use of an Azure Custom Translate model (trained off the fan translation of an earlier game in the series), machine translation quality was variable, and the ergonomics of the whole setup were simply too awkward to apply for the entirety of a 30,000+ line visual novel.
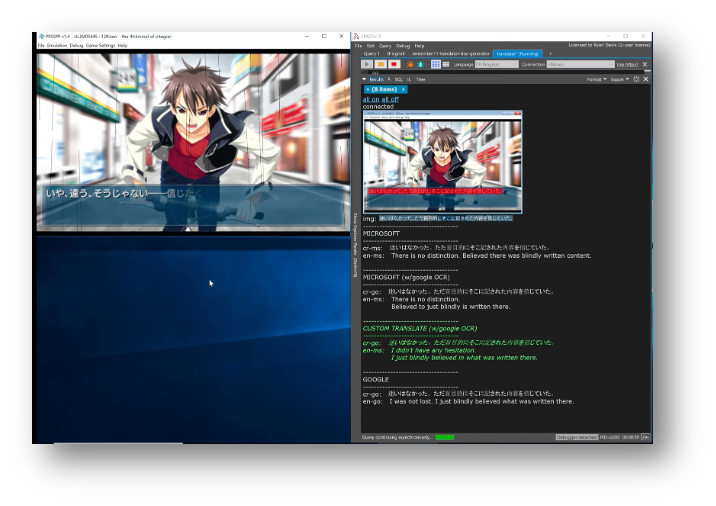
The 2025 approach
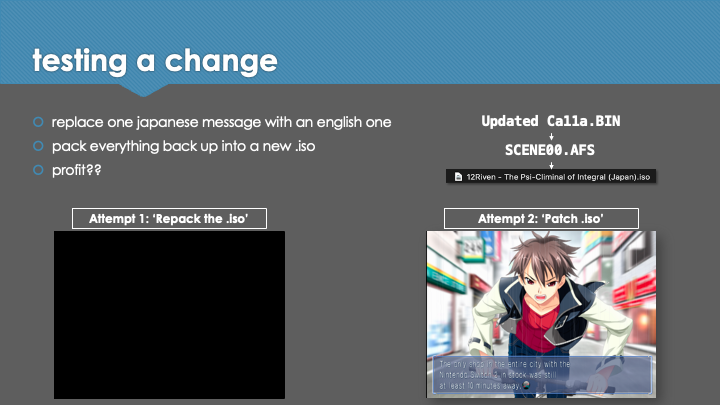
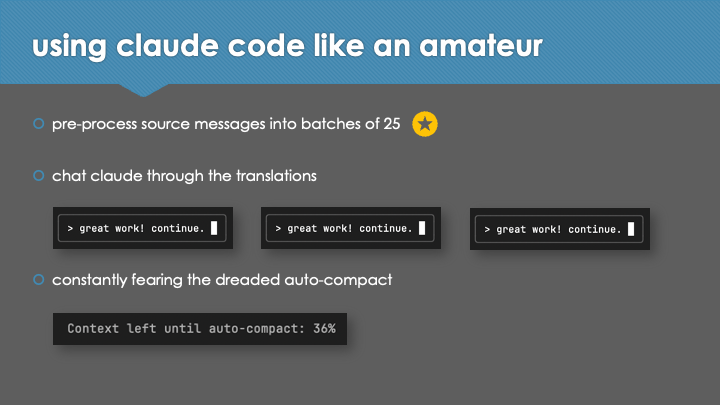
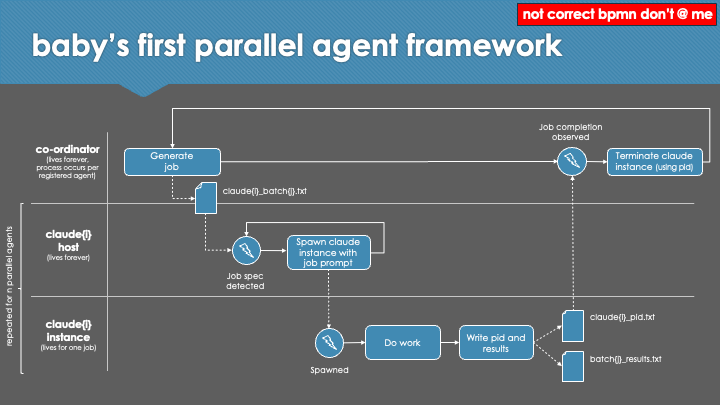
In the session, we looked at how the use of Claude Code significantly improved the approach and outcomes in a second, "vibe translated" attempt. Agentic assistance greatly simplified the process of reverse engineering the game script and generating extraction/reinsertion and repacking utilities, enabling a translation to be applied directly to the game. The switch from machine translation of isolated lines to an llm-based, 'context-aware' translation of batches in sequence, including a multi-pass review process and automatically-maintained translation consistency guide, resulted in a (subjectively) greatly improved quality of translation. The development of a parallel agent framework enabled reliable, unattended, and high throughput translation of the script, in a manner that took advantage of the Claude Code Max subscription usage windows to perform an estimated $1,100 AUD of token usage at zero incremental cost.
Although much code was produced and executed in the process of reverse-engineering, extraction, translation and repacking of the game - no code was written by me. I noticed various suboptimal implementations as I reviewed some of the scripts, prompts, and intermediate outputs while pulling together the slides; but when vibing, "we run the code - we don't judge". The hard work was handled by my good friend Claude Code.
Despite the fact that at first glance this appears to be an excellent and compelling approach towards making a Japanese game accessible to an English speaker, I have to acknowledge that I have no idea of how good or bad the translation output actually is, since I can't read Japanese to verify it. This ties in to a thought I have around cautioning the use of AI to do something you aren't able to do yourself. Beyond the risk involved in taking a dependency on a volatile third-party, it's worth considering that you are unlikely to be able to properly evaluate the quality, completeness, or robustness of an artefact related to a domain you do not understand. This is fine for hobby-level or personal projects, and I will happily use this translation to play the game in the knowledge that it might not be accurate. For anything professional, quite appropriately, a professional translator is called for.
A sample of the translated script in game can be seen in the video below. A few obvious issues, like broken speaker detection and lack of text breaking, were left unfixed to demonstrate that beyond replacing the script, there will typically be fixes required to get a nicely functioning fan translation. I reckon Claude and I can crack those without too much trouble though 😎
Although it is not the right way to translate a videogame, this is adequate for my purposes. It will allow me to achieve one of my life's two dreams - completing the Infinity series - so that I may return my full focus to the other: becoming moderately good at the piano.
Overall, an excellent result.
(P.S. see the addendum for progress on fixing issues)
Slides (63): PDF

|

|

|
|
|
|
Addendum - Fixing Issues
Since the talk, Claude and I have started tackling the remaining issues with the translation. I'll keep this section up to date with progress.
Speaker detection
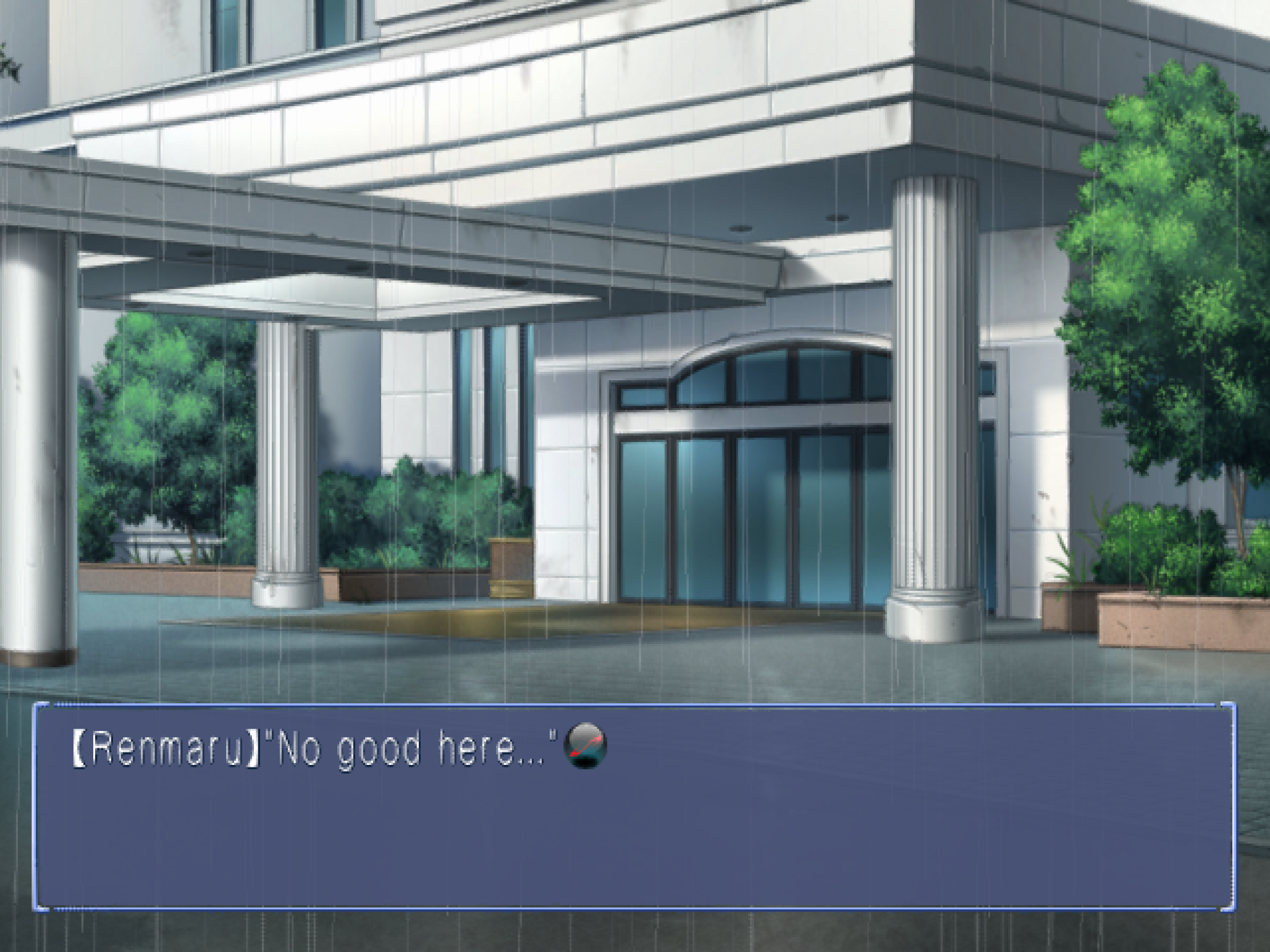
As you'll notice in the video, "speaker detection" is broken in the original translation. The speaker indication appears to be part of script messages (i.e. is not controlled by opcodes/script logic), and is included at the start of messages by placing the speaker name within special brackets. For example:
【Renmaru】"No good here..."
In our early translation attempt, these messages appear with the speaker indication inline in the messagebox. It's wrong, and a bit distracting!
My original hypothesis was that we were missing a space between the special end bracket and our quote mark, which was preventing the speaker name from being lifted to its rightful place. Of course, Claude agreed (it always does), and various fruitless experiments with characters and spacing yielded little success. Claude was convinced that our translation pipeline was breaking the detection by messing with characters, and unfortunately, I had to get my own hands dirty - operating a hex editor myself, like an animal - to prove that incorrect.
After demonstrating that speaker detection worked if we left original Japanese names in the script, I adjusted the hypothesis to be that there must be some reference data elsewhere in the game files, with speakers defined. Tasking out several parallel agents to find references to speaker names in non-core script files found that there was a long list of speaker names in the DATA.BIN file. As an aside, tasking out many parallel agents to search for patterns, or even to try performing the same reverse engineering work analysis on different files, is a really effective way to increase the scope of findings within a fixed period of time. It did not take too much more fiddling to implement a speaker reference data replacement step into our translation pipeline, and now speaker detection works as expected!
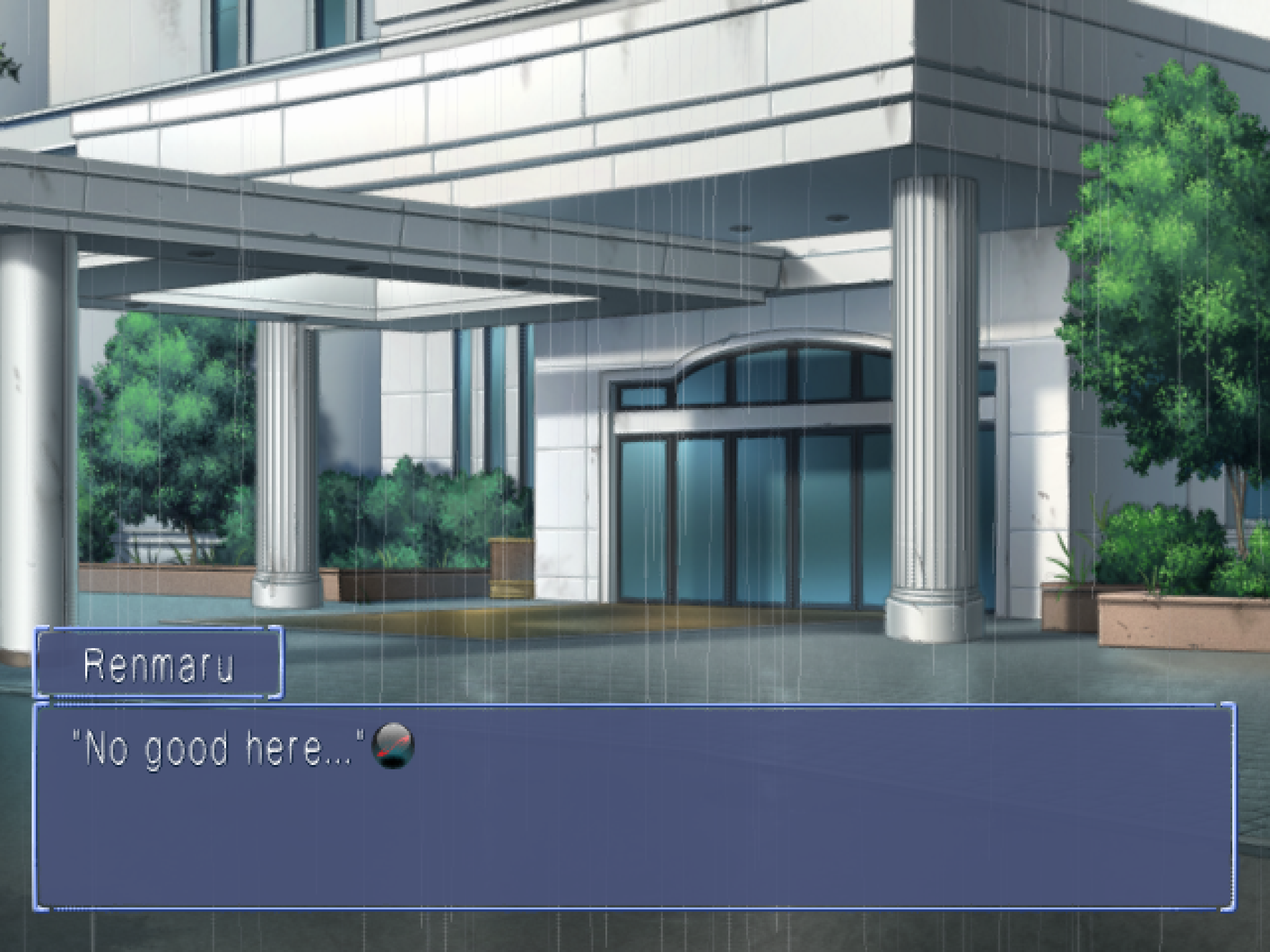
Next up - text wrapping. To quote a timeless phrase:
This story is not yet at an end, the truth is not revealed - It is an infinity loop!